David Patterson had recently mentioned that (rephrasing):
The programmers may benefit from using complex instruction sets directly, but it is increasingly challenging for compilers to automatically generate them in the right spots.
In the last 3-4 years I gave a bunch of talks on the intricacies of SIMD programming, highlighting the divergence in hardware and software design in the past ten years. Chips are becoming bigger and more complicated to add more functionality, but the general-purpose compilers like GCC, LLVM, MSVC and ICC cannot keep up with the pace. Hardly any developer codes in Assembly today, hoping that the compiler will do the heavy lifting.
The code for this article is publicly available in our corporate GitHub profile. Feel free to reuse and reference it!
Crash Course on SIMD
SIMD stands for “Single Instruction Multiple Data”. Those are the Assembly instructions prevalent in modern CISC architectures that guide the CPU to perform identical operations on aligned data pieces in a single logical cycle. The operation may take multiple CPU clock cycles and even trigger CPU frequency degradation, but it is a complex topic that we will not cover this time. Watch this video to learn the whole story.
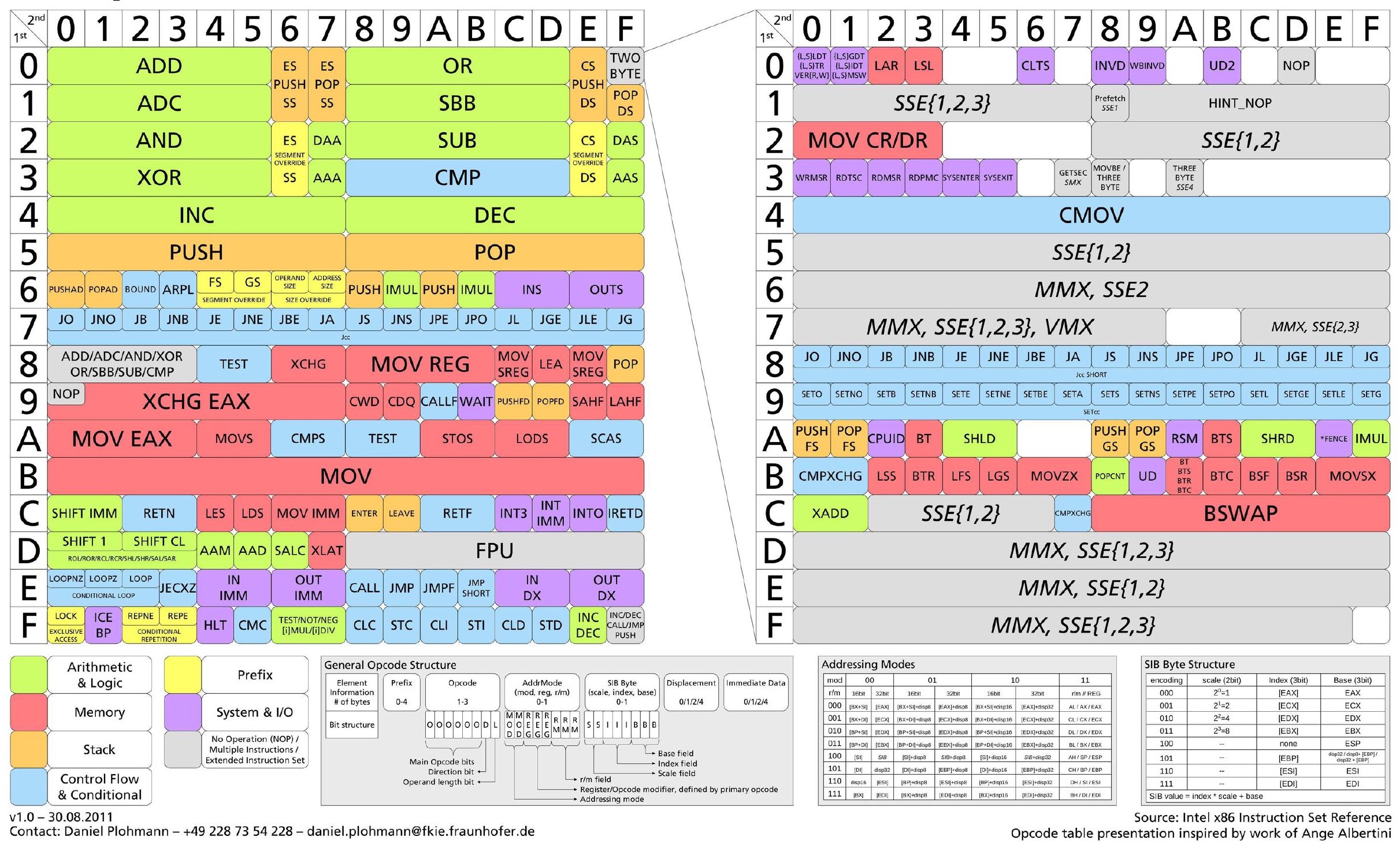
x86 Growth Stages
The data in the table below may not be very accurate but should be good enough to draw a picture. It shows the number of new mnemonics in every generation of SIMD extensions in the x86 ISA.
| Year | Extension | New Mnemonics |
|---|---|---|
| 1997 | MMX | + 46 |
| 1999 | SSE | + 62 |
| 2001 | SSE2 | + 70 |
| 2004 | SSE3 | + 10 |
| 2006 | SSSE3 | + 16 |
| 2006 | SSE4.1/2 | + 54 |
| 2008 | AVX | + 89 |
| 2011 | FMA | + 20 |
| 2013 | AVX2 | + 135 |
| 2015 | AVX-512 | + 347 |
That number had surpassed 1'000 by now and will grow to include AMX soon.
Every mnemonic can have multiple specializations for different register widths, so the number of distinct instructions is now over 4'000!
You can find an almost complete list here.
Five years after the introduction of AVX-512, only a few Intel server CPUs support them. AMD did not implement them in their Epyc lineup.
Linus Torvaldsfamously criticized them in his signature unapologetic manner:
I hope
AVX-512dies a painful death and that Intel starts fixing real problems instead of trying to create magic instructions to then create benchmarks that they can look good on. Linus Torvalds.
Current industry trends are unclear and, regardless of solid opinions, SIMD instructions are here, but are we using them?
How Much Performance Are We Leaving On The Table?
One of my talks was about a simple hack - using AVX2 and a simple heuristic to accelerate substring search to 12 GB/s on a single commodity CPU core.
For reference, libc and STL functions generally only reach 1 GB/s.
While preparing that talk, a team at Intel helped us test and validate the numbers and squeeze the most out of the ICC.
The result - 3 GB/s.
So still 4x slower than the version I have presented back then.
If substring search can be 4x-12x faster, how much faster can the rest of the software be?
Let’s Quantify
First, I wanted to classify all instructions manually. They should be uniquely identifiable by a mnemonic and registers they operate on, but x86 is a CISC for a reason. x86 instructions have variable length limited to 16 bytes. The longest one, however, is only 15 bytes.
Capstone
To make things simpler, I took Capsone, an extremely popular disassembly toolkit. It’s implemented in pure C, but for this little visualization I took the Python wrapper. I used it to parse the instructions and extract the mnemonics. A mnemonic can have a functional suffix, which I drop to make results more interpretable. Here is what our parser looks like:
| |
Wait, Capstone does not classify instructions by their complexity or speed, so we need to do a little bit of preprocessing. As we are currently viewing x86, we should navigate to the Wikipedia page that describes Advanced Vector Extensions. We can see that, unlike the scalar registers, vector registers have very recognizable naming scheme:
- 128-bit registers start with
xmm, - 256-bit registers start with
ymm, - 512-bit registers start with
zmm.
While iterating through binaries, we can check the names of active registers against a pre-compiled vocabulary.
| |
Assuming the operands of an instruction can have different size, we will describe each instruction by the biggest register size involved.
Results
Linux Binaries
I took an AMD Epyc Zen2 machine I had lying around and analyzed all the binaries in /usr/bin and /usr/local/bin.
It’s the latest generation of AMD server CPUs you can buy today. They still don’t support AVX-512, but the AVX-2 instructions are there.
So how many lines of Assembly will at least touch the vector registers that make up one of the most significant parts of the CPU die?
I took around 2'000 binaries, analyzed them with Capstone and exported the statistics for the biggest programs.
| Binary | Instructions | All SIMD | 128-bit SIMD | 256-bit SIMD | 512-bit SIMD |
|---|---|---|---|---|---|
/usr/bin/dockerd | 43M | 0.478% | 0.469% | 0.009% | 0.000% |
/usr/bin/docker | 26M | 0.582% | 0.568% | 0.014% | 0.000% |
/usr/bin/containerd | 21M | 0.560% | 0.543% | 0.017% | 0.000% |
/usr/local/bin/gitlab-runner | 19M | 0.851% | 0.828% | 0.022% | 0.001% |
/usr/bin/mongod | 16M | 0.547% | 0.545% | 0.002% | 0.000% |
/usr/bin/mongoperf | 15M | 0.544% | 0.542% | 0.002% | 0.000% |
/usr/bin/kubectl | 15M | 1.002% | 0.978% | 0.024% | 0.000% |
/usr/bin/helm | 14M | 1.040% | 1.015% | 0.025% | 0.000% |
/usr/bin/ctr | 12M | 0.564% | 0.533% | 0.030% | 0.000% |
/usr/bin/containerd-stress | 10M | 0.551% | 0.516% | 0.035% | 0.000% |
/usr/bin/mongos | 9M | 0.602% | 0.600% | 0.002% | 0.000% |
/usr/bin/mongo | 9M | 0.566% | 0.564% | 0.002% | 0.000% |
/usr/bin/snap | 8M | 0.679% | 0.635% | 0.044% | 0.000% |
macOS Binaries
An argument can be made that Linux packages optimize for compatibility, so the default distributions should support the oldest generations of CPUs. Even in that case, there are ways to ship multiple backends in the same binary, but it is not easy.
What about Mac, then? Of all major Operating Systems, they support the narrowest range of hardware. Before switching to ARM chips recently, they had ten years to optimize their packages and compilers for their hardware.
| Binary | Instructions | All SIMD | 128-bit SIMD | 256-bit SIMD | 512-bit SIMD |
|---|---|---|---|---|---|
| /usr/local/bin/mongod | 26M | 0.636% | 0.635% | 0.001% | 0.000% |
| /usr/local/bin/libHalide.dylib | 25M | 0.289% | 0.288% | 0.001% | 0.000% |
| /usr/local/bin/influxd | 23M | 0.714% | 0.694% | 0.020% | 0.000% |
| /usr/local/bin/influx | 19M | 0.662% | 0.638% | 0.023% | 0.000% |
| /usr/local/bin/hugo | 18M | 0.760% | 0.740% | 0.019% | 0.001% |
| /usr/local/bin/mongo | 17M | 0.614% | 0.613% | 0.002% | 0.000% |
| /usr/local/bin/bazel-real | 16M | 0.141% | 0.120% | 0.020% | 0.000% |
| /usr/local/bin/node | 14M | 0.779% | 0.737% | 0.042% | 0.000% |
| /usr/local/bin/lto-dump-10 | 12M | 0.037% | 0.035% | 0.000% | 0.002% |
| /usr/local/bin/gs-X11 | 8M | 1.168% | 1.167% | 0.000% | 0.001% |
As we see, the picture did not change much.
Final Notes
I will leave everyone to make their own decisions. Today, ARM is shifting from RISC to CISC and already has two very distinct families of SIMD - Neon and SVE. RISC-V is the new RISC on the block, but no-one seems to use them yet. Compilers will probably not get much smarter, but the hardware is changing.
As for current CPUs, there is a lot to optimize even before writing SIMD by hand. To name a few:
- Reduce branching,
- Reduce memory jumps and heap allocations,
- Switch to modern exception handling,
- Avoid run-time polymorphism,
- Make functions more
inline-able, - Tune compilation & linking settings.
This list is not exhaustive. If your bottleneck is I/O - switch from sync to async and then to user-space operations. If you do parallel computing, explore lock-free data structures and read about mutexes vs spin-locks.
Once done, the recommendation would be to focus on 256-bit x86 operations and mainly small integer workloads. These can provide the most considerable boost over the scalar version. So the future-proof variant is to avoid investing too much time into AVX-512 and focus on AVX2 and ARM Neon until the fog is gone and we know what the next generation of hardware brings!