Experienced devs may want to skip the intro or jump immediately to the conclusions.
The backbone of many foundational software systems — from compilers and interpreters to math libraries, operating systems, and database management systems — is often implemented in C and C++. These systems frequently offer Software Development Kits (SDKs) for high-level languages like Python, JavaScript, Go, C#, Java, and Rust, enabling broader accessibility.
But there is a catch. Most of those SDKs are just wrappers calling your standalone application through the networking stack. That is, however, extremely slow. A good networking stack can handle over 100,000 calls per second, while most are below 10,000.
Certain applications demand that C and C++ libraries be invoked millions of times per second. To achieve this high level of performance, the native, pre-compiled library logic must be directly integrated — or embedded — into the target application, regardless of its native language. This integration allows the application and the library to operate within the same OS process and memory address space, bypassing the need for inter-process communication via sockets. This is the realm of language bindings.
This year I’ve open-sourced several data-processing and AI libraries. One of them, USearch, has bindings to 10 programming languages, which is rare and serves as the perfect place to explore some differences between the most common programming languages and, more importantly, their ecosystems.
Moreover, the library implements a data structure that supports concurrent updates and half-precision math, which we will cover in subsequent sections. We will spend a bit more time on Python, the most popular programming language in the world, and highlights some of the issues repeated in other languages.
The project is hosted on GitHub, so to form an enclosed environment, all of the Continuous Integration (CI), including testing and packaging, is happening on GitHub Runners. Core library implementation is in C++11 for compatibility with older C++ toolchains. The bindings are implemented in C++17 for brevity and clarity, as they are pre-compiled in our controlled environment. I prefer the GNU C Compiler (GCC) 12 over default GCC-11 on Ubuntu 22.04, as it doesn’t support some of the Assembly intrinsics I employ in SimSIMD for modern Intel CPUs. I mostly use Sphinx and Doxygen for documentation, and host the result on GitHub Pages. Here is what it looks like.
Bindings
Python
Notable Files
unum-cloud/usearch/setup.pyunum-cloud/usearch/pyproject.tomlunum-cloud/usearch/python/lib.cppunum-cloud/usearch/python/usearch/index.pyunum-cloud/usearch/python/scripts/test_index.py
Implementation
Python is great for working with C/C++ libraries. It has a lot of tools that make life easier:
- Toolchains: SWIG is popular and not just for Python.
- Libraries: You should check out Boost.Python, PyBind11, and NanoBind, made by the same person.
- JIT Compilers: Not so famous but still important are Cppyy and User-Defined Kernels in CuPy. They’re good for Python coders who want to get into C/C++ slowly or for data scientists who want to make their own CUDA kernels for PyTorch.
I usually start with PyBind11, as it takes just one more .cpp file to wrap a library for Python.
But when I need something super fast, like a new kind of string class or a math library for vectors, I go straight to the Python C API.
It’s well explained and once helped me make a project 5 times faster in handling function calls.
PyBind11 is easy to use but sometimes does things you don’t expect, like changing Python’s str to std::string without telling you.
You have more control with the Python C API, but sometimes, it’s still not enough, especially for dealing with Unicode strings without copying them.
I like to use two layers of code when I’m combining Python and C/C++:
- A Python layer that’s easy to read and use,
- And a simple C/C++ layer that does the heavy lifting.
This way, your code is easier to work with in any IDE.
It’s also less messy because you can handle all the checks in Python.
So, in my Python Index class, I create a _CompiledIndex right in the constructor:
Keep in mind:
- Python uses 64-bit for
float, but most people have the NumPy library installed, which can handle 16-bit and 32-bit. - CPython operates in a single-threaded environment and is subject to the Global Interpreter Lock, so you should design your interfaces with batch calls in mind, spawning native threads under the hood.
- For other Python runtimes like PyPy, Jython, or IronPython, you’ll need different bindings.
Packaging
For simple builds and purely Python packages, a setup.py file is all you need.
But if you want your native package to work on different Operating Systems and Python versions, you’d use something like cibuildwheel and make a pyproject.toml file.
Remember, this part can take a long time in GitHub CI:
- Windows takes 6.5 minutes for the bindings and 1.5 minutes for the C library.
- macOS takes 19 minutes for the bindings and 1 minute for the C library.
- Linux takes the longest, 43 minutes for the bindings and 1 minute for the C library.
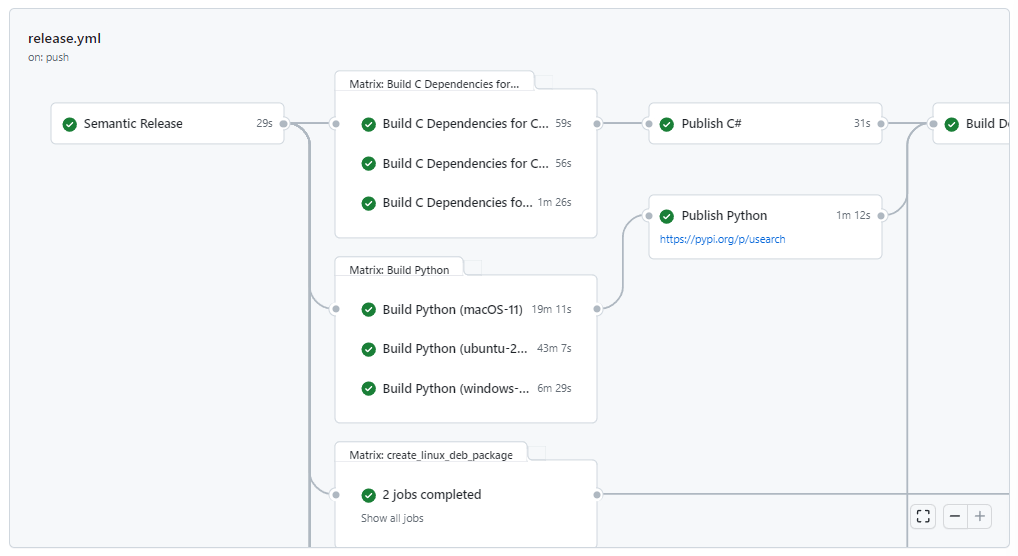
Uploading to PyPI is easy to automate.
Anaconda is a bit harder and might not be worth it, especially since Conda can use PyPI too.
As part of the CI, I run tests both for the core implementation and the bindings.
In Python, I use the pytest utility, which automatically discovers the relevant files and, coupled with pytest-repeat, helps me run fuzzy tests on such probabilistic data structures.
| |
JavaScript
Notable Files
unum-cloud/usearch/package.jsonunum-cloud/usearch/bindings.gypunum-cloud/usearch/javascript/lib.cppunum-cloud/usearch/javascript/usearch.jsunum-cloud/usearch/javascript/usearch.test.js
Implementation
Node.js makes it pretty straightforward to link with C++ and C code.
The process is similar to Python; you usually only need one .cpp file for the whole thing.
Then, you’ll write a .js file, which can be as simple as:
| |
For USearch, I built it out more, creating a two-tiered binding. The JavaScript and Python environments share a lot of similarities:
- JavaScript doesn’t have half-precision float support, offering just
Float32ArrayandFloat64Array. - Node.js, like CPython, is single-threaded, so all functions in the API are designed to support batch requests.
- Different JavaScript environments, such as Bun or Deno, might need their own bindings — I’m guessing a bit here.
I tried TypeScript for the API, but matching it with Sphinx documentation proved too tricky.
Packaging
To set up your project, you’ll want to use a JSON-like language to make a bindings.gyp file.
This method, along with the node-gyp tool, which handles these files, actually comes from the Chromium project.
The syntax is a bit odd to me, and is inconsistent if you want to forward environment variables into compilation settings:
[
'OS=="linux"',
{
"cflags_cc": [
'<!(if [ "$USEARCH_USE_OPENMP" = "1" ]; then echo \'-fopenmp\'; fi)',
],
"ldflags": [
'<!(if [ "$USEARCH_USE_OPENMP" = "1" ]; then echo \'-lgomp\'; fi)'
],
"defines": [
"USEARCH_USE_OPENMP=<!(echo ${USEARCH_USE_OPENMP:-0})",
"USEARCH_USE_SIMSIMD=<!(echo ${USEARCH_USE_SIMSIMD:-1})",
"USEARCH_USE_FP16LIB=<!(echo ${USEARCH_USE_FP16LIB:-1})",
"SIMSIMD_TARGET_X86_AVX512=<!(echo ${SIMSIMD_TARGET_X86_AVX512:-1})",
"SIMSIMD_TARGET_ARM_SVE=<!(echo ${SIMSIMD_TARGET_ARM_SVE:-1})",
"SIMSIMD_TARGET_X86_AVX2=<!(echo ${SIMSIMD_TARGET_X86_AVX2:-1})",
"SIMSIMD_TARGET_ARM_NEON=<!(echo ${SIMSIMD_TARGET_ARM_NEON:-1})",
],
},
]
That comes handy, when users want to deploy your libraries in less common environments like the stateless AWS Lambda functions. For Windows and Linux the syntax is different. Uploading to the Node Package Manager (NPM) was straightforward.
Rust
Notable Files
unum-cloud/usearch/Cargo.tomlunum-cloud/usearch/build.rsunum-cloud/usearch/rust/lib.rsunum-cloud/usearch/rust/lib.hppunum-cloud/usearch/rust/lib.cpp
Implementation
I’ve used FFI to bind a C++ library, initially keeping all the implementations on the C++ side.
Here is how lib.rs file starts:
Later I switched to a 2-level approach using traits, as I wanted to overload the same add & search functions to support i8, f32, f64 types without paying the runtime costs.
Together with a minimalistic test, the Rust part of the binding grew to over 600 lines, with another 200 lines of C++ code under the hood.
- Rust doesn’t support half-precision floats.
- Rust supports parallelism, so we haven’t had to implement batch requests.
Packaging
As for testing, package uploads, and overall developer experience, Rust is great. For documentation, it has a separate portal - docs.rs.
ObjC and Swift
Notable Files
unum-cloud/usearch/Package.swiftunum-cloud/usearch/swift/USearch.swiftunum-cloud/usearch/swift/Index+Sugar.swiftunum-cloud/usearch/swift/Test.swiftunum-cloud/usearch/objc/include/USearchObjective.hunum-cloud/usearch/objc/USearchObjective.mm
Implementation
Swift is just starting to support experimental C++ interoperability. Until today, you had to bridge them with ObjC. With extensive previous experience in ObjC, the process was simple. ObjC doesn’t support overloading the same function name with different argument types, while Swift does. Same for half-precision math. So my Objective-C header defines:
| |
Using NS_SWIFT_NAME macro I define the symbol names for the Swift runtime, and later wrap them again to simplify the names.
Note the syntax Swift provides to limit half-precision only on recent versions:
| |
Packaging
Swift has no separate package manager and most dependencies are pulled directly from GitHub. There is, however, a Swift Package Index, that helps developers discover your package.
Go
Notable Files
unum-cloud/usearch/golang/go.modunum-cloud/usearch/golang/lib.gounum-cloud/usearch/golang/lib_test.go
Implementation
For Go, the go-to method is using cGo, which lets you include native code right in your Go programs.
You place build instructions within comments next to the import "C" statement.
My first try at lib.go seemed straightforward:
However, the experience is a bit unusual.
Go struggles with direct C++ use, which is why I’m using a .h C binding instead of the original .hpp C++ header.
Also, I link to a pre-compiled C library, which is outside of Go’s build system.
Users need to manually install usearch_c.so from our CI release assets before they can use it in their app like this:
What’s more, the delay introduced by cGo can be quite high. For very quick operations like those in SimSIMD or StringZilla, the overhead of switching from Go’s concurrency to C’s function stack-frame might be way too much.
- Like most languages, Go supports
float32andfloat64types, but doesn’t havefloat16. - Since Go handles parallel tasks well, I didn’t need to build batch processing capabilities.
Packaging
Go doesn’t use a separate package manager; it pulls most dependencies directly from repositories like GitHub.
Once you create a go.mod file, your package should get picked up and indexed on pkg.go.dev.
There, automatically generated docs are also available.
Java
Notable Files
unum-cloud/usearch/build.gradleunum-cloud/usearch/java/cloud/unum/usearch/Index.javaunum-cloud/usearch/java/cloud/unum/usearch/cloud_unum_usearch_Index.hunum-cloud/usearch/java/cloud/unum/usearch/cloud_unum_usearch_Index.cppunum-cloud/usearch/test/IndexTest.java
Implementation
We connect to the C++ library using Java Native Interface (JNI). We use Bazel for building the shared library. This method is widely accepted. Your Java library will include a step to load the native shared library:
Sharing Java packages can be really confusing.
You may need to learn Groovy to write a proper build.gradle for Bazel.
But users will usually add your library as a dependency with an XML snippet, like so:
There are many places to register your package, and the main ones have several steps. To get on Sonatype, you must request access on a forum, wait for approval, and then use the Nexus Maven Central portal. Every new push lands in a “staging” area. To move forward, you must “close” it first and then “release” after checks are done. The whole process is far from intuitive.
C 99
Notable Files
unum-cloud/usearch/c/usearch.hunum-cloud/usearch/c/lib.cppunum-cloud/usearch/c/test.cunum-cloud/usearch/CMakeLists.txtunum-cloud/usearch/c/CMakeLists.txt
Implementation
For small projects, C is perfect. It gets even better if you can limit yourself to only using the GNU C Compiler with all the extensions, including:
- Nested functions, similar to C++ lambdas.
- Zero-length arrays.
- Binary constants using the
0bprefix. - Zero-sized empty structures and unnamed fields.
- Built-in safe math and atomics.
- 128-bit integers and 16-bit floats.
Some are also available on Clang, but I can’t use them in most of my libraries.
As time passes, C is adopting some nifty features from C++, like the auto keyword coming in C 23.
Packaging
This would have been funny if it wasn’t so sad, but C and C++ still don’t have good tooling, despite being some of the oldest languages on the list.
I’ve seen/tried Bazel, Conan, Vcpkg, Premake, Buck2, and several other options.
They all have their pros and cons, but none of them are as easy to use as Python’s setup.py.
CMake is one of the most popular, but it’s a nightmare.
The nightmare millions of developers experience every night.
That being said, C and C++ are still the only languages that get my work done. As you can imagine, many suggest Rust as a replacement, but I’m not convinced. Most of my code would be in unsafe sections, and I’d have to write boilerplate code to achieve the same performance. Python + C/C++/Assembly is still the best combination for me.
Overall Impressions
Let’s keep C# and Wolfram for another comparison and highlight some common patterns.
GitHub
Big ones:
- GitHub Actions are a nightmare to debug. Patching those YML configs is tricky, especially if you want to keep a clean Git history and don’t have an army of DevOps Pros to help.
- Search and discoverability of multi-package projects is poor. If people search for “tensorflow language:Python”, they’ll not find the repo, as it’s mostly implemented in C++, despite having over 179,000 stars and close to 3,500 contributors. Don’t ask me how that’s possible. Still, would be great to index and highlight the packages across different languages, if those are backed by the same monorepo.
| TensorFlow | PyTorch | USearch |
|---|---|---|
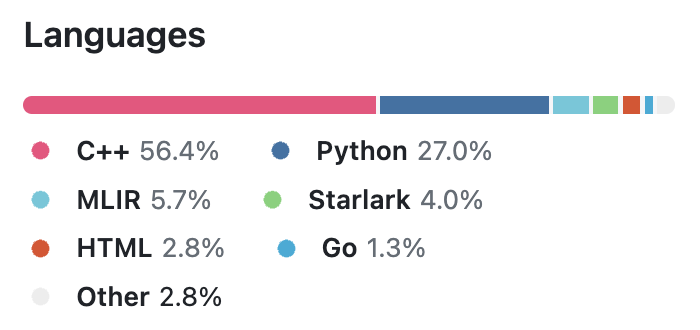 |  |  |
Nice to haves:
- GitHub provides a Maven registry for Java packages. It’s very easy to upload to, but none of the Java developers I’ve met know how to use it.
- Low-level libraries are often included as Git submodules, as the package managers are poorly developed. Would be great to index those for the dependency graph.
The latter may have a surprisingly large affect at the industry. I believe we, as a developer community, have introduced too many layer of abstractions without recognizing the costs every new level brings. Highlighting the usage of a low-level C library, same way as Python and NPM packages are highlighted, may encourage more people to contribute to the core library, peeling off a few layers of abstractions in the long run.
Multi-Architecture Builds
- Multi-Architecture Builds are complicated. Shipping both x86 and Arm binaries as part of one package is largely unaddressed by most ecosystems. Apple has an advantage over Microsoft here. Shocking.
- One of those architectures is WebAssembly. Specialized package managers for Wasm are popping up, but it would have been much easier if NPM and PyPI could handle WASM natively. Another big problem with WASM, its still a 32-bit architecture, which severely limits its usability.
- If you want to ship packages with bindings for different generations of the CPUs, I don’t know a good solution for that either.
The last issue is partially solved in GCC with “Function Multiversioning”. It’s not portable between compiler, but looks like this, if you are not familiar:
Not unrelated is the issue of standardizing the numeric types available across different systems.
- Both C and C++ as well as many other languages don’t have sized numeric types (like
i64in Rust) as part of the language. Those often come in libraries. So if you want to avoid any dependencies including LibC and STL, you’d have to define those yourself. - Half-precision math, so important in modern AI workloads, is largely unsupported on most platforms and in most languages.
- Similarly, most databases use 128-bit integers for their IDs, most recent hardware supports them, but languages rarely do.
Too Many DSLs and Custom Tools
The plethora of custom DSLs for builds and packages is overwhelming. You have to learn Make/CMake languages to compile a C/C++ project. Similarly you learn Groovy to write Bazel files to compile a Java wrapper for a C/C++ native library.
Often, a custom dependency manager is necessary just to begin, as system packages can be outdated. For up-to-date Java, there’s SDKMAN!:
| |
For the latest NodeJS, you might use Node Version Manager:
| |
Conclusion
Getting our software to communicate across many programming languages turned out to be quite a challenge. Simple connections are straightforward enough, but aiming for low latency and continuous testing ramps up the complexity significantly. Often, the trouble isn’t even in our code but in the myriad systems it interacts with.
In this landscape, ChatGPT has been invaluable. With precise inquiries, it is as a force multiplier, akin to doubling your team’s size, minus the communication overhead.
Despite the advantages provided by ChatGPT, we’re not aiming to replicate this extensive integration with languages in other Unum projects such as UCall or UForm. Similarity Search, however, is an exception. It sits in that sweet spot: fundamental enough to be in high demand across applications, yet sophisticated enough to not be a default offering in programming languages. Moving forward, I’m focusing on:
- Fuzzy Full Text Search in USearch v3.
- New indexing algorithm for v4.
Stay connected for what’s on the horizon – github, linkedin, twitter, or by subscribing to the newsletter 🤗
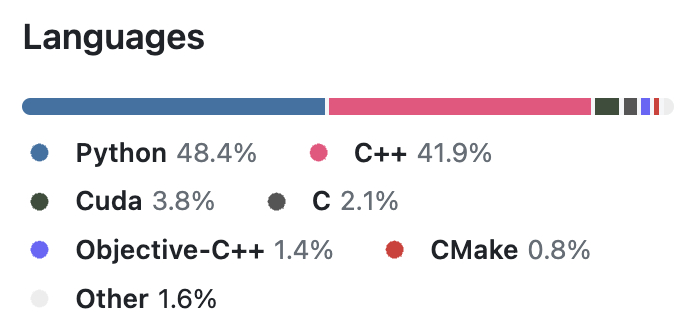
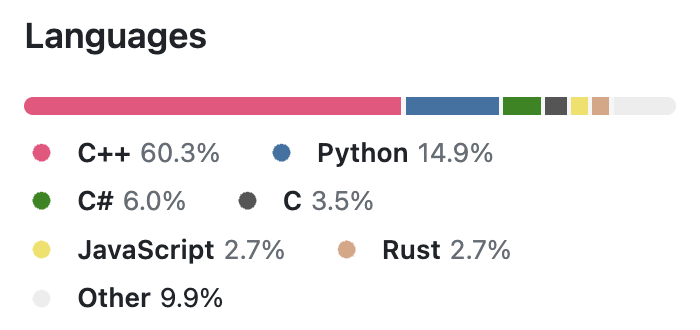
As a bonus, here is a breakdown of a recent USearch release by different languages, as reported by the cloc utility:
| |