Python has a straightforward syntax for positional and keyword arguments.
Positional arguments are arguments passed to a function in a specific order, while keyword arguments are passed to a function by name.
Surprising to most Python developers, the choice of positional vs keyword arguments can have huge implications on readability and performance.
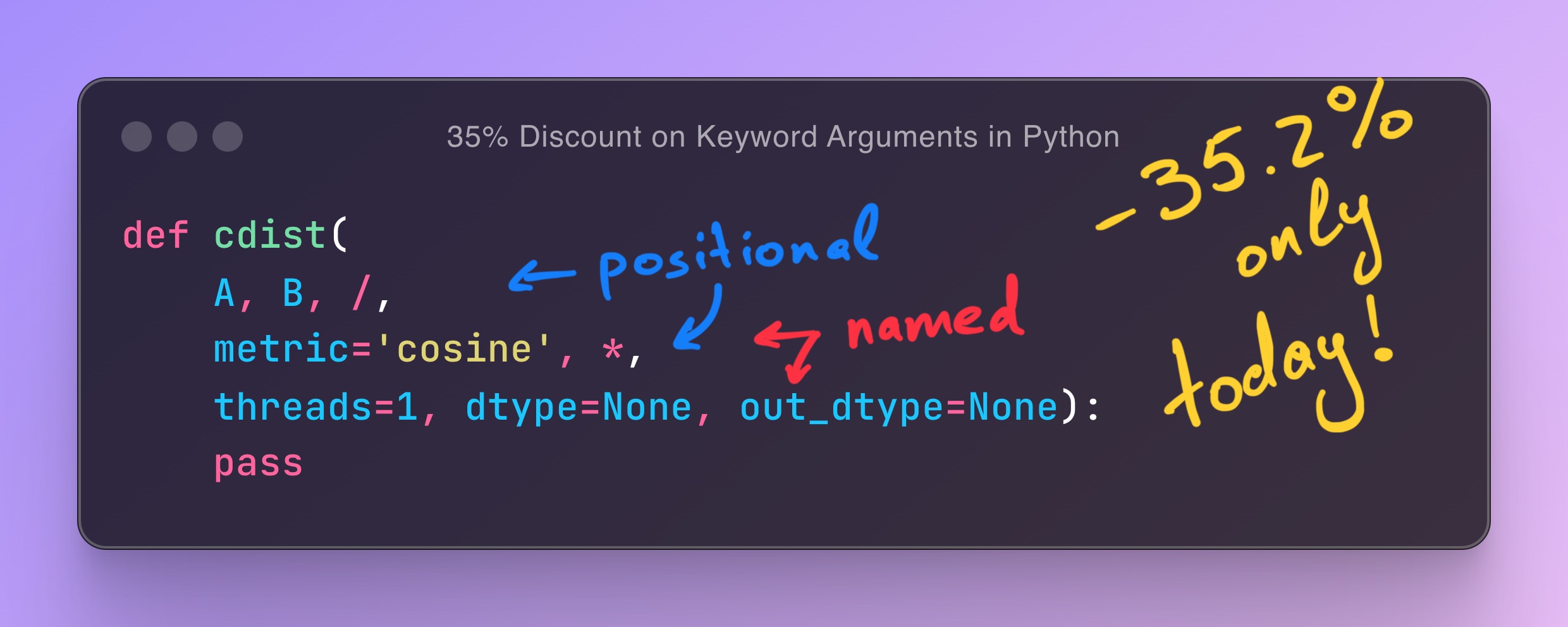
Let’s take the cdist interface as an example.
It’s a function implemented in SimSIMD, mimicking SciPy, that computes all pairwise distances between two sets of points, each represented by a matrix.
It accepts up to 6 arguments:
- 2 positional arguments,
A and B, represent the two point sets. - 1 argument, which can be either positional or keyword,
metric, that specifies the distance metric to use. - 3 keyword-only arguments
threads, dtype, and out_dtype that specify the number of threads to use, the input matrices’ data type, and the output matrix’s data type, respectively.
This article aims to profile the cost of parsing arguments in Python. Still, before one dives into performance optimizations, it’s essential to understand the design principles of a good API and why the current cdist declaration in __init__.pyi looks the way it does.
Good Design Principles#
Ideally, the interface of a function should make it really hard to misuse.
What happens if we abuse the interface and pass all arguments as positional?
1
2
3
4
| cdist() # TypeError: cdist() missing 2 required positional arguments: 'A' and 'B'
cdist(A) # TypeError: cdist() missing 1 required positional argument: 'B'
cdist(A, B=B) # TypeError: cdist() got some positional-only arguments passed as keyword arguments: 'B'
cdist(A, B, '', 1) # TypeError: cdist() takes from 2 to 3 positional arguments but 4 were given
|
Coming from C++, this error message is constructive.
Now, how do we preserve sanity?
Avoiding *args and **kwargs#
One of Python’s most common “code smells” is abusing *args and **kwargs.
Those allow you to pass an arbitrary number of positional and keyword arguments to a function.
1
2
3
4
5
6
| >>> def process_data(*args, **kwargs):
... print(f"Processing {len(args)} positional arguments of type {type(args)}")
... print(f"Processing {len(kwargs)} keyword arguments of type {type(kwargs)}")
... for key, value in kwargs.items():
... print(f"- {key}: {value}")
>>> process_data(10, 11, a=12, b=13)
|
Which will output:
1
2
3
4
| Processing 2 positional arguments of type <class 'tuple'>
Processing 2 keyword arguments of type <class 'dict'>
- a: 12
- b: 13
|
While such variadic arguments can be helpful in some cases, they add a layer of obscurity.
The reader is forced to look at the function definition to understand what arguments are expected.
In many cases, the reader will need to jump through multiple files to understand the function’s behavior.
Just look at this object-oriented mess and ask yourself how many times you’ve seen something like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class BaseAction:
def __init__(self, *args, **kwargs):
self.user = kwargs.get('user', 'guest')
self.verbose = kwargs.get('verbose', False)
def execute(self, *args, **kwargs):
print(f"Executing base action as {self.user}")
if self.verbose:
print("Verbose mode in base action")
class FileCleanupAction(BaseAction):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.file_path = kwargs.get('file_path', None)
def execute(self, *args, **kwargs):
print(f"Cleaning up file: {self.file_path}")
super().execute(*args, **kwargs)
class DatabaseBackupAction(BaseAction):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.db_name = kwargs.get('db_name', None)
def execute(self, *args, **kwargs):
print(f"Backing up database: {self.db_name}")
super().execute(*args, **kwargs)
|
Some of the most familiar repositories in the AI space, like Hugging Face’s Transformers and LangChain, struggle from this problem.
Handling arguments like that would make our life easier, but the experience of the end-user would be a nightmare, so there is not a single *args or **kwargs in the SimSIMD __init__.pyi.
Default Arguments and Type Annotations#
Assuming you explicitly list all arguments in the function signature, the next natural step is to add default values and type annotations.
1
2
3
4
5
| from typing import List
def f(x: List = []):
x += (len(x),)
return x
|
There are a few pitfalls with this code.
First, type annotations in Python have no effect on the runtime, so you may as well pass in a tuple or a set, and the code will still work.
Second, the default values are evaluated at the time of the function definition, not at the time of the call.
This means the following will be printed:
1
2
3
4
5
| print(f()) # [0]
print(f()) # [0, 1]
print(f(tuple())) # (0,)
print(f()) # [0, 1, 2]
print(f(set())) # `TypeError: unsupported operand type(s) for +=: 'set' and 'tuple'`
|
A nice footgun, but there are other ways to encounter problems.
My favorite is the missing library dependencies or mismatched Python versions.
1
2
3
4
5
6
7
8
9
10
| from typing import Optional, TypeAlias
from numpy.typing import NDArray
MetricType: TypeAlias = Literal['cosine', 'sqeuclidean']
def cdist(
A: NDArray, B: NDArray, /,
metric: MetricType = 'cosine', *,
threads: int = 1, dtype: Optional[str] = None, out_dtype: Optional[str] = None) -> NDArray:
pass
|
Python 3.10 introduced a typing.TypeAlias to help the LSP servers and static type checkers understand the code better.
Without it, PyLance would raise:
Variable not allowed in type expression
Integrating the type alias was easy, but in Python 3.12, the TypeAlias was deprecated in favor of the type statement, which creates instances of TypeAliasType and natively supports forward references.
That type statement is only available in Python 3.12, so you’d have to wait for the next release to get rid of the warning or handle a special case.
Moreover, the Literal type was introduced in Python 3.8, and the numpy.typing.NDArray was introduced in NumPy 1.21.
Let’s simplify our code a bit:
1
2
3
4
5
6
7
8
| from typing import Optional
from numpy import ndarray
def cdist(
A: ndarray, B: ndarray, /,
metric: str = 'cosine', *,
threads: int = 1, dtype: Optional[str] = None, out_dtype: Optional[str] = None) -> ndarray:
pass
|
If you are maintaining an extremely cross-platform library, this is also problematic.
As of September 9, 2024, the latest version of NumPy is v2.1.1, and the latest version of SimSIMD is v5.1.0.
So if we were to introduce np.ndarray symbols into our type annotations, we’d have to recompile NumPy sources for the 53 missing targets.
Most compilations don’t currently pass in cibuildwheel, the default tool for building Python wheels.
One way to avoid that is to use the native memoryview type, the Python counterpart of the underlying CPython buffer protocol.
That interface will make your code more portable and compatible with other Tensor libraries, like PyTorch and TensorFlow.
1
2
3
4
5
6
7
| from typing import Optional
def cdist(
A: memoryview, B: memoryview, /,
metric: str = 'cosine', *,
threads: int = 1, dtype: Optional[str] = None, out_dtype: Optional[str] = None) -> memoryview:
pass
|
Lesson?
Don’t be too smart with your type annotations, and don’t rely on the latest features of Python, if you are maintaining a library that is supposed to be used by a wide audience.
In SimSIMD, for now, we assume the used Python version is 3.11 or similar, and configure the type annotations accordingly.
No type statements for now.
With the design principles out of the way, let’s talk performance.
How Most Native Packages Handle Arguments#
PyArg_ParseTuple and PyArg_ParseTupleAndKeywords#
Python is a dynamic language, and the CPython objects are designed to be as flexible as possible.
This flexibility comes at a cost, and the price is the performance.
- Most property lookups in CPython (1) are dictionary traversals, expensive string comparisons, and memory allocations.
- Most precompiled native (C/C++) extensions rely on high-level wrapper libraries like PyBind11 to handle argument parsing, which is even slower.
Leaving (2.) out of the picture and just focusing on the recommended way of doing things, we open the CPython documentation page to see this:
The first three of these functions described, PyArg_ParseTuple(), PyArg_ParseTupleAndKeywords(), and PyArg_Parse(), all use format strings which are used to tell the function about the expected arguments. The format strings use the same syntax for each of these functions.
Using them in a C native extension isn’t that hard.
One needs to lookup format specifiers, to learn that O is for arbitrary objects, s is for strings, and K is for unsigned long long integers:
1
2
3
4
5
6
7
8
9
10
11
12
| static PyObject* api_cdist(PyObject* self, PyObject* args, PyObject* kwargs) {
PyObject* input_tensor_a = NULL; // Required object, positional-only
PyObject* input_tensor_b = NULL; // Required object, positional-only
char const* metric_str = NULL; // Optional string, positional or keyword
unsigned long long threads = 1; // Optional integer, keyword-only
char const* dtype_str = NULL; // Optional string, keyword-only
char const* out_dtype_str = NULL; // Optional string, keyword-only
static char* kwlist[] = {"input_tensor_a", "input_tensor_b", "metric", "threads", "dtype", "out_dtype", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "OO|s$Kss", kwlist, &input_tensor_a, &input_tensor_b, &metric_str,
&threads, &dtype_str, &out_dtype_str))
return NULL;
|
Then, we recompile SimSIMD and run the following simple script:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import numpy as np
from simsimd import cdist
a = np.random.randn(16).astype("float16")
b = np.random.randn(16).astype("float16")
for _ in range(10_000_000):
cdist(
a,
b,
metric="sqeuclidean",
threads=1,
dtype="float16",
out_dtype="float64",
)
|
Timing it on a modern Intel Sapphire Rapids CPU, we get:
1
2
3
4
| $ time python dispatch.py
> real 0m5.592s
> user 0m6.875s
> sys 0m0.018s
|
What if we comment out the optional arguments like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import numpy as np
from simsimd import cdist
a = np.random.randn(16).astype("float16")
b = np.random.randn(16).astype("float16")
for _ in range(10_000_000):
cdist(
a,
b,
# metric="sqeuclidean",
# threads=1,
# dtype="float16",
# out_dtype="float64",
)
|
… and re-run the script:
1
2
3
4
| $ time python dispatch.py
> real 0m2.281s
> user 0m3.509s
> sys 0m0.013s
|
We’ve just halfed the execution time, performing the same logic.
So yes, argument parsing isn’t free!
Manually Unpacking Arguments#
PyTuple_GetItem and PyDict_GetItem#
We can do better than PyArg_ParseTupleAndKeywords by manually unpacking the arguments.
It’s just a tuple and a dictionary, after all.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| static PyObject* api_cdist(PyObject* self, PyObject* args, PyObject* kwargs) {
// This function accepts up to 6 arguments:
PyObject* input_tensor_a = NULL; // Required object, positional-only
PyObject* input_tensor_b = NULL; // Required object, positional-only
PyObject* metric_obj = NULL; // Optional string, positional or keyword
PyObject* threads_obj = NULL; // Optional integer, keyword-only
PyObject* dtype_obj = NULL; // Optional string, keyword-only
PyObject* out_dtype_obj = NULL; // Optional string, keyword-only
if (!PyTuple_Check(args) || PyTuple_Size(args) < 2 || PyTuple_Size(args) > 3) {
PyErr_SetString(PyExc_TypeError, "Function expects 2-3 positional arguments");
return NULL;
}
input_tensor_a = PyTuple_GetItem(args, 0);
input_tensor_b = PyTuple_GetItem(args, 1);
if (PyTuple_Size(args) > 2)
metric_obj = PyTuple_GetItem(args, 2);
// Checking for named arguments in kwargs
if (kwargs) {
threads_obj = PyDict_GetItemString(kwargs, "threads");
dtype_obj = PyDict_GetItemString(kwargs, "dtype");
out_dtype_obj = PyDict_GetItemString(kwargs, "out_dtype");
int count_extracted = (threads_obj != NULL) + (dtype_obj != NULL) + (out_dtype_obj != NULL);
if (!metric_obj) {
metric_obj = PyDict_GetItemString(kwargs, "metric");
count_extracted += metric_obj != NULL;
} else if (PyDict_GetItemString(kwargs, "metric")) {
PyErr_SetString(PyExc_ValueError, "Duplicate argument for 'metric'");
return NULL;
}
// Check for unknown arguments
int count_received = PyDict_Size(kwargs);
if (count_received > count_extracted) {
PyErr_SetString(PyExc_ValueError, "Received unknown keyword argument");
return NULL;
}
}
// Once parsed, the arguments will be stored in these variables:
char const* metric_str = NULL;
unsigned long long threads = 1;
char const* dtype_str = NULL;
char const* out_dtype_str = NULL;
// The rest is pretty much the same, except for some type checks for `metric_obj`,
// `threads_obj`, `dtype_obj`, and `out_dtype_obj`.
|
Recompiling SimSIMD and running the script:
1
2
3
4
| $ time python dispatch.py
> real 0m4.489s
> user 0m5.805s
> sys 0m0.019s
|
We’ve just gone from 6.875s to 5.805s, a 15% speedup.
Good start.
Manually Unpacking in a Single Pass#
PyDict_Next and PyUnicode_CompareWithASCIIString#
We have called PyDict_GetItemString many times, and it is a dictionary lookup.
A dictionary can be implemented as a hash table, and the lookup time is O(1), but the constant factor is still there.
We can do it in a single loop, assuming we plan to assign all passed arguments to variables.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| static PyObject* api_cdist(PyObject* self, PyObject* args, PyObject* kwargs) {
// This function accepts up to 6 arguments:
PyObject* input_tensor_a = NULL; // Required object, positional-only
PyObject* input_tensor_b = NULL; // Required object, positional-only
PyObject* metric_obj = NULL; // Optional string, positional or keyword
PyObject* threads_obj = NULL; // Optional integer, keyword-only
PyObject* dtype_obj = NULL; // Optional string, keyword-only
PyObject* out_dtype_obj = NULL; // Optional string, keyword-only
if (!PyTuple_Check(args) || PyTuple_Size(args) < 2 || PyTuple_Size(args) > 3) {
PyErr_SetString(PyExc_TypeError, "Function expects 2-3 positional arguments");
return NULL;
}
input_tensor_a = PyTuple_GetItem(args, 0);
input_tensor_b = PyTuple_GetItem(args, 1);
if (PyTuple_Size(args) > 2)
metric_obj = PyTuple_GetItem(args, 2);
// Checking for named arguments in kwargs
if (kwargs) {
Py_ssize_t pos = 0;
PyObject* key;
PyObject* value;
while (PyDict_Next(kwargs, &pos, &key, &value)) {
if (PyUnicode_CompareWithASCIIString(key, "threads") == 0) {
if (threads_obj != NULL) {
PyErr_SetString(PyExc_ValueError, "Duplicate argument for 'threads'");
return NULL;
}
threads_obj = value;
} else if (PyUnicode_CompareWithASCIIString(key, "dtype") == 0) {
if (dtype_obj != NULL) {
PyErr_SetString(PyExc_ValueError, "Duplicate argument for 'dtype'");
return NULL;
}
dtype_obj = value;
} else if (PyUnicode_CompareWithASCIIString(key, "out_dtype") == 0) {
if (out_dtype_obj != NULL) {
PyErr_SetString(PyExc_ValueError, "Duplicate argument for 'out_dtype'");
return NULL;
}
out_dtype_obj = value;
} else if (PyUnicode_CompareWithASCIIString(key, "metric") == 0) {
if (metric_obj != NULL) {
PyErr_SetString(PyExc_ValueError, "Duplicate argument for 'metric'");
return NULL;
}
metric_obj = value;
} else {
PyErr_Format(PyExc_ValueError, "Received unknown keyword argument: %O", key);
return NULL;
}
}
}
// Once parsed, the arguments will be stored in these variables:
char const* metric_str = NULL;
unsigned long long threads = 1;
char const* dtype_str = NULL;
char const* out_dtype_str = NULL;
|
We can also avoid unpacking the strings, by using the PyUnicode_CompareWithASCIIString for comparison.
Recompiling SimSIMD and running the script:
1
2
3
4
| $ time python dispatch.py
> real 0m3.572s
> user 0m4.806s
> sys 0m0.013s
|
We’ve just gone from 5.805s to 4.806s, another 17% speedup.
Faster Calling Conventions#
METH_FASTCALL and METH_KEYWORDS#
In PEP 590 “Vectorcall” convention was added to CPython for callables.
There is also a METH_FASTCALL flag for defining _PyCFunctionFast functions and a combination of METH_FASTCALL | METH_KEYWORDS for defining _PyCFunctionFastWithKeywords functions.
1
2
3
4
5
6
7
8
9
10
| PyObject *_PyCFunctionFast(
PyObject *self,
PyObject *const *args,
Py_ssize_t nargs);
PyObject *_PyCFunctionFastWithKeywords(
PyObject *self,
PyObject *const *args, // positional arguments in a C-style array of pointers
Py_ssize_t nargs, // number of positional arguments in the prefix of `args`
PyObject *kwnames); // named arguments in the tail of `args`, forming a Python `tuple`
|
Using the latter, we can further optimize our argument parsing to avoid dictionaries altogether.
The tricky part is that the total number of elements in the C-style args array is a sum nargs + PyTuple_Size(kwnames).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| static PyObject* api_cdist(PyObject* self, PyObject* const* args, Py_ssize_t args_count, PyObject* kwnames) {
// This function accepts up to 6 arguments:
PyObject* input_tensor_a = NULL; // Required object, positional-only
PyObject* input_tensor_b = NULL; // Required object, positional-only
PyObject* metric_obj = NULL; // Optional string, positional or keyword
PyObject* threads_obj = NULL; // Optional integer, keyword-only
PyObject* dtype_obj = NULL; // Optional string, keyword-only
PyObject* out_dtype_obj = NULL; // Optional string, keyword-only
if (args_count < 2 || args_count > 6) {
PyErr_Format(PyExc_TypeError, "Function expects 2-6 arguments, got %d", args_count);
return NULL;
}
// Positional-only arguments
input_tensor_a = args[0];
input_tensor_b = args[1];
// Positional or keyword arguments
Py_ssize_t args_progress = 2;
Py_ssize_t kwnames_progress = 0;
Py_ssize_t kwnames_count = PyTuple_Size(kwnames);
if (args_count > 2 || kwnames_count > 0) {
metric_obj = args[2];
if (kwnames) {
PyObject* key = PyTuple_GetItem(kwnames, 0);
if (key != NULL && PyUnicode_CompareWithASCIIString(key, "metric") != 0) {
PyErr_SetString(PyExc_ValueError, "Third argument must be 'metric'");
return NULL;
}
args_progress = 3;
kwnames_progress = 1;
}
}
// The rest of the arguments must be checked in the keyword dictionary
for (; kwnames_progress < kwnames_count; ++args_progress, ++kwnames_progress) {
PyObject* key = PyTuple_GetItem(kwnames, kwnames_progress);
PyObject* value = args[args_progress];
if (PyUnicode_CompareWithASCIIString(key, "threads") == 0) {
if (threads_obj != NULL) {
PyErr_SetString(PyExc_ValueError, "Duplicate argument for 'threads'");
return NULL;
}
threads_obj = value;
} else if (PyUnicode_CompareWithASCIIString(key, "dtype") == 0) {
if (dtype_obj != NULL) {
PyErr_SetString(PyExc_ValueError, "Duplicate argument for 'dtype'");
return NULL;
}
dtype_obj = value;
} else if (PyUnicode_CompareWithASCIIString(key, "out_dtype") == 0) {
if (out_dtype_obj != NULL) {
PyErr_SetString(PyExc_ValueError, "Duplicate argument for 'out_dtype'");
return NULL;
}
out_dtype_obj = value;
} else {
PyErr_Format(PyExc_ValueError, "Received unknown keyword argument: %S", key);
return NULL;
}
}
// The rest is pretty much the same, except for some type checks for `metric_obj`,
|
Recompiling SimSIMD and running the script:
1
2
3
4
| $ time python dispatch.py
> real 0m3.141s
> user 0m4.453s
> sys 0m0.023s
|
We’ve just gone from 4.806s to 4.453s, another 7% speedup.
All in all, we’ve managed to reduce the execution time from 6.875s to 4.453s, a 35.2% overall speedup.
Here we go, a 35% discount on keyword arguments in Python!
Conclusion#
Optimizing argument parsing in Python may seem like a niche pursuit, but as we’ve seen, it can yield significant performance gains in high-demand applications.
These techniques aren’t just theoretical; they have practical implications for real-world systems.
Most SimSIMD kernel wrappers now use fast calling conventions, and the performance improvements are especially noticeable for the sparse operations added in SimSIMD v5.1, which are very common in high-throughput information retrieval systems.
This kind of optimization really shines in the context of primitive types, like custom strings.
So, the next natural step after checking out the ashvardanian/SimSIMD repository - may be diving into the ashvardanian/StringZilla
The latter contains a lot of more advanced techniques, implementing the primary __dunder__ methods, with a detailed 3000-lines-long C to CPython binding.
Sounds cool?
Check out the “good first issues” and join the force 😉
If you want to check all the versions yourself, here are the commits for each optimization: