GPU acceleration can be trivial for Python users.
Follow CUDA installation steps carefully, replace import numpy as np with import cupy as np, and you will often get the 100x performance boosts without breaking a sweat.
Every time you write magical one-liners, remember a systems engineer is making your dreams come true.
A couple of years ago, when I was giving a talk on the breadth of GPGPU technologies, I published a repo.
A repo with various cool GPGPU staff in Vulkan, Halide, and most importantly, 8x implementations of std::accumulate in OpenCL.
I know what you are thinking:
Eight ways to sum numbers?! Are you 🌰s?!
Don’t worry! We are now back with more! No more OpenCL, no more SyCL. This time we focus on Parallel STL, SIMD, OpenMP and, of course, CUDA, CUB and Thrust!
You can find all the sources hosted on our GitHub. Benchmarks were run with the newest stable versions of software available at the time: Ubuntu 20.04, GCC 10.3, CUDA Toolkit 11.6, Thrust 1.15, oneTBB 2021.5 and TaskFlow 3.3.
This article went through 2 updates. First, the OpenMP numbers were corrected. Later, I reflected on the results and came to a shocking conclusion. It thematically belongs in the middle, but I published it separately to avoid spoilers and keep it chronological.
C++ and STL
The canonical serial solution for this problem in C and C++ would be:
For simple tasks like this, there is also an STL version.
Let’s put a sample an example with 1 GB worth of float numbers:
Time for some trivia questions. What will be the sum?
Due to rounding errors, the result of sequential accumulation will be significantly less accurate than doing it in batches or parallel tree-like reductions.
To avoid it, you would need more memory.
One more float for the compensation part, as in the Kahan summation algorithm.
Or simply using a double for the accumulation.
The latter being equally fast on modern x86 chips and easier to implement:
- 5.2 GB/s when accumulating into
float, with a 93% error. - 5.3 GB/s when accumulating into
double, with a 0% error.
SIMD: AVX2
We also implemented three AVX2 SIMD variants for intra-thread acceleration:
- Naive 8x lane
floataccumulation. - Kahans 8x lane
floataccumulation. - Conversions and 4x lane
doubleaccumulation.
They all utilize heavy instructions, so some downclocking occurs, but performance is excellent, and rounding errors disappear in the last two variants. The (1) and (3) SIMD code is trivial. We will only post the Kahan version for clarity.
| |
Results on a single CPU core:
- 22.3 GB/s naively accumulating
float, with a 50% error. - 10.9 GB/s accumulation with Kahans method, with 0% error.
- 17.0 GB/s accumulating as
doubles, with 0% error.
OpenMP
Not to be confused with OpenMPI, Open Multi-Processing is probably the oldest Multi-Threading (not Multi-Processing!) standard.
It has run on anything from desktops to supercomputers since 1997 and is widely supported by Fortran, C and C++ compilers.
Aside from the oldest #pragmas, they also support parallel reductions:
We tried every OpenMP reduction tutorial but couldn’t make it work faster than the most basic serial version of std::accumulate.
Result: 5.4 GB/s.
Update on OpenMP
After a few recommendations on Reddit, an issue with compilation flags was resolved.
At 100% CPU utilization OpenMP scored 51.5 GB/s.
After that, we disabled dynamic scheduling with omp_set_dynamic(0) and reduced the number of threads, reaching the result of 80 GB/s.
Parallel Algorithms
STL ships with std::execution policies since 17th edition.
Hope being, that multi-threaded <algorithm>s are easy to use and at least as good as average parallel code.
| |
Result: 5.3 GB/s.
Wait, it’s the same as we got for single-threaded code.
We forgot that GCC relies on Intel’s Thread Building Blocks to implement parallel algorithms.
Let’s update our CMakeLists.txt:
Run again and hurray!
- 80 GB/s in
std::execution::parreductions. - 87 GB/s in
std::execution::par_unseqreductions.
Now we are going somewhere! Can we go there faster?
SIMD + Threads
If we take our AVX2 SIMD (#3) implementation and spawn 64x std::threads, whenever a new task comes, we can still go a little faster: 89 GB/s.
In the best-case scenario, if we always had a thread-pool around, with ~20 idle threads, we could do even better, up to 200 GB/s.

Not more. Not until we switch from DDR4 to DDR5 and from 8-channel to 12-channel RAM. Extrapolating the Hash-Table benchmarks of Apple M1 Max laptops, we can expect massive boosts in DDR5-powered servers. Sapphire Rapids may even get in-package High Bandwidth Memory, but for now, only GPUs have that!
Switching to GPUs
It would have been interesting to run the same OpenCL scripts on both CPUs and GPUs. Unfortunately, we lost that opportunity about two years ago, when AMD dropped support for OpenCL in their CPU lineup. As we are only limited to a GPU, we will skip OpenCL this time, assuming that, on average, its kernels are at least 30% slower than CUDA.
| GPU Model | Size | Type | Bus | Bandwidth |
|---|---|---|---|---|
| 3090 | 24 GB | GDDR6X | 384 bit | 936 GB/s |
| 3090 Ti | 24 GB | GDDR6X | 384 bit | 1'018 GB/s |
| A100 SXM4 | 80 GB | HBM2e | 5120 bit | 2'039 GB/s |
Before starting our experiment, let’s determine our upper bound. The A100 is a datacenter GPU, and 3090 Ti hasn’t reached the market yet, so we won’t get 1 TB/s this time around.
CUDA with SHFL
There is the old way “to CUDA” and the new way.
The old one uses just __shared__ memory.
The post-Kepler method recommends using shuffles for thread scheduling.
| |
This sample more or less repeats the CUDA tutorial but replaces the deprecated __shfl_down with __shfl_down_sync in the first function.
Mouthful, compared to std::accumulate, but it gets the work done: 817 GB/s 💣💣
Thrust
Thrust might just be my favorite high-level library. Generic enough to be considered an STL extension and full of intrguing technical solutions. If you don’t want to write a custom kernel for a GPU, you can probably compose a multi-round alternative with Thrust.
| |
The result: 743 GB/s. A 9% reduction, compared to the hand-written kernel, but hardly slow.
Those of us waiting for NVCC implementation of Parallel Algorithms will use it indirectly.
Others can use it directly or go one paragraph layer lower to CUB.
CUB
CUBs main benefit is stricter control over memory allocations. Parallel and concurrent algorithms often require extra memory compared to serial analogues. To keep the interface familiar and straightforward, Thrust may allocate temporary memory internally.
With CUB, you manage memory yourself and control the algorithm selection more explicitly, resulting in faster code but a much heavier codebase. For example, you would typically call the same function twice. First time only to estimate the needed temporary memory capacity.
| |
CUB provides shortcuts for the most common binary commutative operators: sum, min, max, argmin, argmax.
So instead of invoking cub::DeviceReduce::Reduce in this case, we run cub::DeviceReduce::Sum.
Result: 879 GB/s 🔥🔥🔥
CUB is an excellent library by itself - a huge productivity booster.
Especially the device-scale functions, like DeviceHistogram, DevicePartition, DeviceRadixSort, DeviceRunLengthEncode, DeviceScan.
Our internal on-GPU compression library, for example, has a multi-stage pipeline, where parts were initially written with Thrust.
Then accelerated with CUB and only in most important places, rewritten in raw CUDA.
Tensor Cores
This is one of those cases where Tensor Cores can’t help us much.
We can program the wmma:: intrinsics in CUDA directly.
In that case, we can reshape the input array into a very long matrix and multiply it by small auto-generated matrices on the fly.
Every wmma::fragment<wmma::matrix_b, 16, 16, 8, wmma::precision::tf32, wmma::row_major> would contain mostly zeros, except the first column of ones.
Every warp would perform its reduction, accumulating 16²=256 numbers into a column of 16 sums.
One per row.
It’s a lot of wasted compute capacity, but given the insane efficiency of Tensor Cores, we could have gotten a slight improvement.
Still, assuming we have already reached 94% of theoretical memory bandwidth, we are definitely in the red zone of diminishing returns.
Roundup
We repeated the benchmarks for every power-of-two array size between 32 MB and 4 GB. If an image is worth a thousand words to you, enjoy!
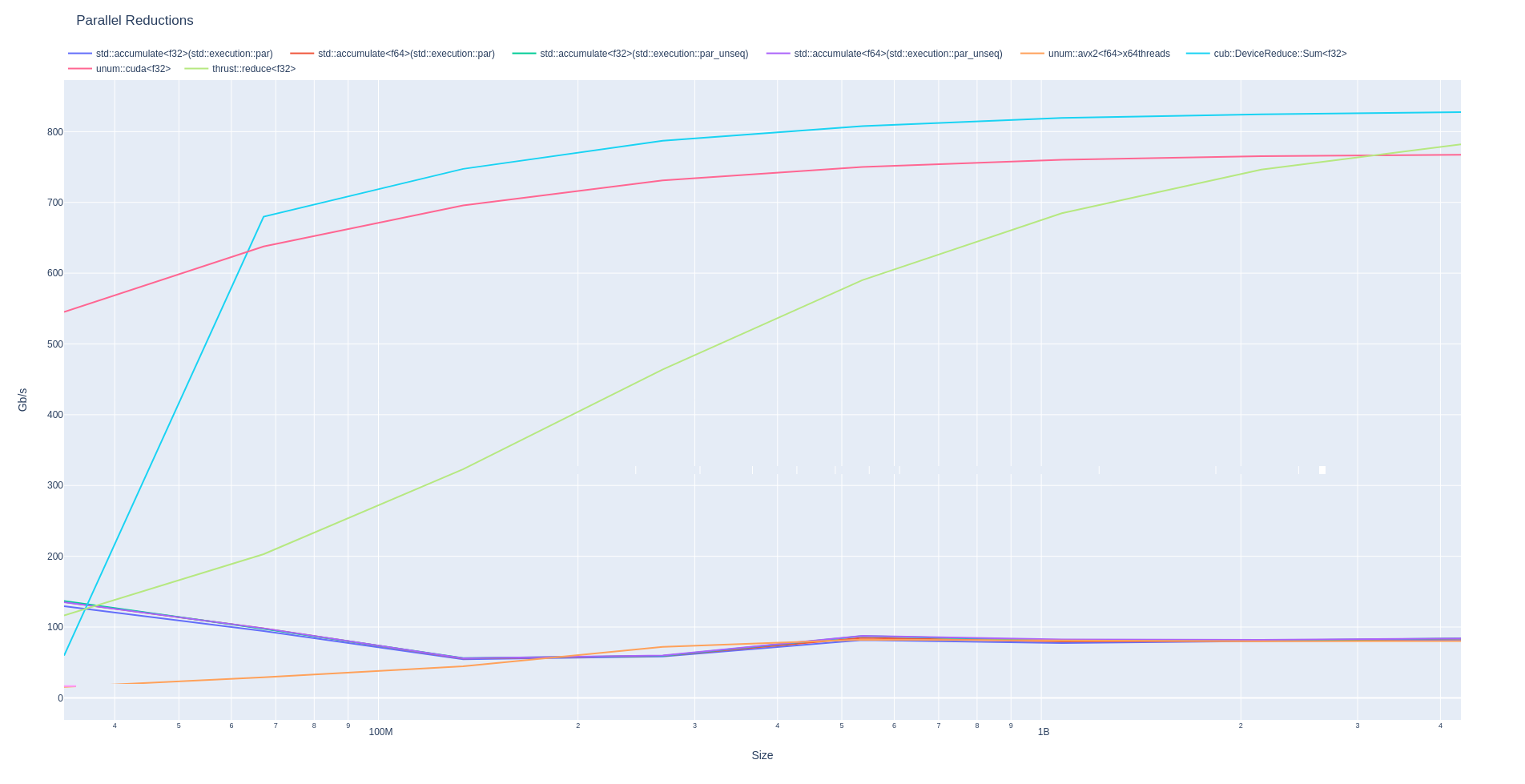
Again, if you are curious to see how your CPU/GPU would compete, here is the GitHub link for these benchmarks. It should be pretty easy to install if you have ever used CMake.
Intel is preparing its Ponte Vecchio GPU launch. And AMD is trying to attract more customers for their MI200 GPUs. With all that action, we should expect more first-party HPC libraries, like Thrust and CUB. Before then, we will keep reinventing the wheel, often implementing stuff from scratch and writing about it occasionally. All to accelerate AI research and build the fastest persistent DBMS the world as ever seen 😉